排序
sort函数(sort和cmp配合使用)
sort函数(c++)可以对数据进行排序和自定义排序(cmp配合使用)
1 2 3 4 5 从小到大排序可以写成sort (a,a+n,less <要进行排序的数据类型>())sort (a,a+n,greater <要进行排序的数据类型>())
sort可以和cmp函数配合使用进行自定义的结构体排序:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 typedef struct char name[100 ];double a,b,c;double sum;bool cmp (const student &a,const student &b) if (a.sum!=b.sum) return a.sum>b.sum;else if (a.a!=b.a) return a.a>b.a;else if (a.b!=b.b) return a.b>b.b;else return a.c>b.c;int main () 10 ];sort (a,a+n,cmp);
堆排序
分析1:为什么从无序数组创建堆要从n/2开始?
因为堆为完全二叉树,完全二叉树中父亲和儿子的地址拥有如下关系:父亲X2=左儿子,父亲X2+1=右儿子,左儿子/2=右儿子/2=父亲 。
分析2:升序和降序如何选择大根堆或者小根堆?
在升序中通常采用小根堆,在降序中采用大根堆。因为用数组模拟堆时,删除首元素比较麻烦,但是删除最后一个元素非常方便,直接让首元素等于最后一个元素,然后在不断down首元素得到正确的堆
分析3:为什么在down()函数中要不断递归呢?
因为创建堆的时候,当父亲比两个儿子都大的时候,我们找到三个中最小的一个,并交换位置,但是我们并不知道父亲在整个堆的位置,所以我们要不断down来正确找到父亲的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <string> #include <queue> using namespace std;const int N=1e5 +10 ;int h[N],tt;void down (int x) int t=x;if (2 *x<=tt&&h[2 *x]<h[t]) t=2 *x;if (2 *x+1 <=tt&&h[2 *x+1 ]<h[t]) t=2 *x+1 ;if (t!=x)swap (h[x],h[t]);down (t);int main () int n,m;sync_with_stdio (false );for (int i=1 ;i<=n;i++) cin>>h[i];for (int i=n/2 ;i>0 ;i--) down (i);for (int i=1 ;i<=m;i++)1 ]<<" " ;1 ]=h[tt--];down (1 );return 0 ;
桶排序
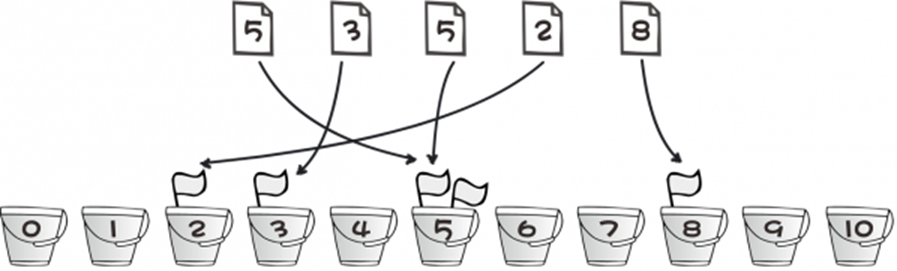
桶排序可以解决数据过多导致超时的情况,也可以计算计算得票数量类的题型
整个过程:
例题:
1 2 3 4 5 6 为了找出林大2020新生中最擅长编写代码的同学,学校发起了一场投票。通过同学报名、前期遴选等环节,共提名了100名同学作为选举人进行评选,假设他们的编号从1到100。现在学院已经采集到了n名同学的投票结果,请你找出得票最多的程序员获得的票数(注:就是让你找相同数字的个数的最大值)。 2 4 7 7 7 5 5 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <bits/stdc++.h> #include <algorithm> using namespace std;int a[200 ];int main () int n,t;while (cin>>n)memset (a,0 ,sizeof (a));for (int i=1 ;i<=n;i++){int ans=0 ;for (int i=1 ;i<=100 ;i++) ans=max (ans,a[i]);return 0 ;
快速排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 785 .快速排序n 的整数数列。n 。n 个整数(所有整数均在 1 ∼109 范围内),表示整个数列。n 个整数,表示排好序的数列。1 ≤n ≤100000 5 3 1 2 4 5 1 2 3 4 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> using namespace std;const int N=1e5 +10 ;int a[N];void quick_sort (int a[],int l,int r) if (l>=r) return ;int i=l-1 ,j=r+1 ,x=a[l+r>>1 ];while (i<j)do i++;while (a[i]<x);do j--;while (a[j]>x);if (i<j) swap (a[i],a[j]);quick_sort (a,l,j);quick_sort (a,j+1 ,r);int main () int n;for (int i=0 ;i<n;i++) scanf ("%d" ,&a[i]);quick_sort (a,0 ,n-1 );for (int i=0 ;i<n;i++) i==n-1 ?cout<<a[i]<<endl:cout<<a[i]<<" " ;return 0 ;
归并排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 787 .归并排序n 的整数数列。n 。n 个整数(所有整数均在 1 ∼109 范围内),表示整个数列。n 个整数,表示排好序的数列。1 ≤n ≤100000 5 3 1 2 4 5 1 2 3 4 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;const int N=1e6 +10 ;int q[N],tmp[N];void merge_sort (int l,int r) if (l>=r) return ;int mid=l+r>>1 ;merge_sort (l,mid),merge_sort (mid+1 ,r);int k=0 ,i=l,j=mid+1 ;while (i<=mid&&j<=r)if (q[i]<q[j]) tmp[k++]=q[i++];else tmp[k++]=q[j++];while (i<=mid) tmp[k++]=q[i++];while (j<=r) tmp[k++]=q[j++];for (k=0 ,i=l;i<=r;i++,k++) q[i]=tmp[k];int main () int n;for (int i=0 ;i<n;i++) cin>>q[i];merge_sort (0 ,n-1 );for (int i=0 ;i<n;i++) i==n-1 ?cout<<q[i]<<endl:cout<<q[i]<<" " ;return 0 ;
选择排序O(N^2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 787 .归并排序n 的整数数列。n 。n 个整数(所有整数均在 1 ∼109 范围内),表示整个数列。n 个整数,表示排好序的数列。1 ≤n ≤100000 5 3 1 2 4 5 1 2 3 4 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> using namespace std;const int N=1e6 ;int a[N];int main () int n;for (int i=0 ;i<n;i++) cin>>a[i];for (int i=0 ;i<n-1 ;i++)for (int j=i+1 ;j<n;j++)if (a[i]>a[j]) swap (a[i],a[j]); for (int i=0 ;i<n;i++) cout<<a[i]<<" " ;return 0 ;
冒泡排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <string> #include <algorithm> using namespace std;#define MAXSIZE 1000; int a[1000 ];void bubble_sort (int n) for (int i=0 ;i<=n;i++)bool flag=true ;for (int j=0 ;j<n-i;j++){if (a[j]>a[j+1 ]){swap (a[j],a[j+1 ]);false ;if (flag) break ;int main () int n=0 ;int data;while (scanf ("%d" ,&data)!=EOF)if (!data){break ;else a[n++]=data;bubble_sort (n);for (int i=0 ;i<=n;i++) cout<<a[i]<<" " ;return 0 ;
直接插入算法
算法核心
从第二个元素开始,一旦有元素a[j-1]>a[j],那么就需要调整顺序。
先将a[j]存储到a[0],然后将a[j]=a[j-1],接着从j-2后往前比对,如果a[j]>a[0],那么就将a[j+1]=a[j],如果a[j]<=a[0],那么a[j+1]=a[0],结束本轮循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <algorithm> #include <string> using namespace std;#define MAXSIZE 1000; int a[1000 ];void DirectInsertSort (int n) int j;for (int i=2 ;i<=n;i++)if (a[i]<a[i-1 ])0 ]=a[i];-1 ];for (j=i-2 ;a[0 ]<a[j];j--) a[j+1 ]=a[j];1 ]=a[0 ];int main () int n=1 ;int data;while (scanf ("%d" ,&data)!=EOF)if (!data){break ;else a[n++]=data;DirectInsertSort (n);for (int i=1 ;i<=n;i++) cout<<a[i]<<" " ;return 0 ;
二进制枚举
详细介绍二进制枚举
1.含有N个元素的集合的一切子集个数有2^n种,二进制采用0和1来表示数字。于是我们可以利用二进制特性,将含n个元素都用0和1来表示选和不选,于是就可以得到每一种子集的情况。
2.那我们如何找到每个位置是否选和不选?可以采用位运算和与运算结合的方式。<<运算相当于在01串的尾巴处加上0(左移一位相当于乘以2),而与运算的规则是全为1才可以得到1。那么我们就可以通过对1不断进行左移运算和与运算得到每个位置的选择情况
1 2 3 4 5 6 7 1 <<1 =2 (10 ); 1000 &0010 =0000 1 <<2 =4 (100 ); 1000 &0100 =0000 1 <<3 =8 (1000 ); 1000 &1000 =1000 1 <<4 =16 (10000 ); 01000 &10000 =00000
例题:
和为K–二进制枚举
1 2 3 4 5 6 7 8 9 10 11 12 Description
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;int main () int n,k;while (cin>>n>>k)int a[n];for (int i=0 ;i<n;i++) cin>>a[i];int flag=1 ;for (int i=0 ;i<(1 <<n);i++)int sum=0 ;for (int j=0 ;j<n;j++)if (i&(1 <<j)) sum+=a[j];if (sum==k){"Yes" <<endl;0 ;break ;if (flag) cout<<"No" <<endl;return 0 ;
陈老师加油-二进制枚举
1 2 3 4 5 6 7 8 9 10 11 12 Description
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <bits/stdc++.h> #include <algorithm> using namespace std;int main () int n;while (cin>>n)int ans=0 ;for (int i=0 ;i<(1 <<15 );i++)int a=0 ,b=0 ,tmp=n;for (int j=0 ;j<15 ;j++)if (i&(1 <<j)){2 ;else {1 ;if (tmp<=0 ) break ;if (tmp==0 &&a==5 &&b==10 ) ans++;return 0 ;
权利指数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Description
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <bits/stdc++.h> #include <algorithm> using namespace std;int main () int k;while (k--)int x,a[20 ],sum=0 ,flag[20 ],b[20 ],ans;memset (b,0 ,sizeof (b));for (int i=0 ;i<x;i++){for (int i=0 ;i<(1 <<x);i++)memset (flag,0 ,sizeof (flag));0 ;for (int j=0 ;j<x;j++)if (i&(1 <<j))1 ;}if (ans<=sum/2 ){for (int z=0 ;z<x;z++)if (flag[z]==0 &&ans+a[z]>sum/2 ) b[z]++;for (int i=0 ;i<x-1 ;i++) cout<<b[i]<<" " ;-1 ]<<endl;return 0 ;
二分
整数二分
二分模板1:(求下标最小的x)
1 2 3 4 5 6 7 8 while (l<r)int mid=l+r>>1 ;if (a[mid]>=x) r=mid;else l=mid+1 ;
二分模板2:(求下标最大的x)
1 2 3 4 5 6 7 8 while (l<r)int mid=l+r+1 >>1 ;if (a[mid]<=x) l=mid;else r=mid-1 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 789 数的范围-1 -1 。-1 -1 。-1 -1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;const int N=1e5 +10 ;int q[N],n,m;int main () for (int i=0 ;i<n;i++) scanf ("%d" ,&q[i]);while (m--)int k;int l=0 ,r=n-1 ;while (l<r){int mid=l+r>>1 ;if (q[mid]>=k) r=mid;else l=mid+1 ;if (q[l]!=k) cout<<"-1 -1" <<endl;else " " ;int l=0 ,r=n-1 ;while (l<r){int mid=l+r+1 >>1 ;if (q[mid]<=k) l=mid;else r=mid-1 ;return 0 ;
浮点数二分
模板
1 2 3 4 5 6 7 while (r-l>1e-6 )2 ;if (check (mid)) r=mid;else l=mid;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 给定一个浮点数 n ,求它的三次方根。n 。6 位小数。10000 ≤n ≤10000 1000.00 10.000000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> using namespace std;int main () double x;double l=-10000 ,r=10000 ;while (r-l>1e-8 )double mid=(l+r)/2 ;if ((mid*mid*mid)>=x) r=mid;else l=mid;printf ("%.6lf" ,l);return 0 ;
高精度
高精度加法
高精度加法关键在于将每一位数字拆解,然后逆向存入数组里(比如输入进来1234,在传入数组中的时候值为4321,然后再利用小学数学加法的知识,每一位数字的值为A[I]+B[I]+t(t为进位的值),循环进行直到遍历到数组a和b的结束位置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 给定两个正整数(不含前导 0),计算它们的和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> #include <vector> #include <string> using namespace std;vector<int > add (const vector<int >&A,const vector<int >&B) int > C;int t=0 ;for (int i=0 ;i<A.size ()||i<B.size ();i++)if (i<A.size ()) t+=A[i];if (i<B.size ()) t+=B[i];push_back (t%10 );10 ;if (t) C.push_back (1 );return C;int main () int >A,B;for (int i=a.size ()-1 ;i>=0 ;i--) A.push_back (a[i]-'0' );for (int i=b.size ()-1 ;i>=0 ;i--) B.push_back (b[i]-'0' );auto C=add (A,B);for (int i=C.size ()-1 ;i>=0 ;i--) cout<<C[i];return 0 ;
leetcode66题
1 2 3 4 5 6 66. 加一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public :vector<int > plusOne (vector<int >& digits) {int > ans;int t=1 ;for (int i=digits.size ()-1 ;i>=0 ;i--)push_back (t%10 );10 ;if (t) ans.push_back (1 );reverse (ans.begin (),ans.end ());return ans;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public :vector<int > plusOne (vector<int >& digits) {int i=digits.size ()-1 ;while (i>=0 &&digits[i]==9 )0 ;if (i==-1 ) digits.insert (digits.begin (),1 );else digits[i]+;return digits;
leetcode第二题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 2 . 两数相加0 之外,这两个数都不会以 0 开头。1 :[2,4,3] , l2 = [5,6,4] [7,0,8] 342 + 465 = 807 .2 :[0] , l2 = [0] [0] 3 :[9,9,9,9,9,9,9] , l2 = [9,9,9,9] [8,9,9,9,0,0,0,1] [1, 100] 内0 <= Node.val <= 9
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public :ListNode* addTwoNumbers (ListNode* l1, ListNode* l2) {new ListNode (-1 ),*pMove=head;int t=0 ;while (l1||l2||t)if (l1) t+=l1->val;if (l2) t+=l2->val;new ListNode (t%10 );10 ;if (l1) l1=l1->next;if (l2) l2=l2->next;return head->next;
高精度减法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 给定两个正整数(不含前导 0),计算它们的差,计算结果可能为负数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <vector> #include <string> using namespace std;bool cmp (vector<int >&A,vector<int >&B) if (A.size ()!=B.size ()) return A.size ()>B.size ();else for (int i=A.size ();i>=0 ;i--)if (A[i]!=B[i]) return A[i]>B[i];return true ;vector<int > sub (const vector<int >&A,const vector<int >&B) int >C;for (int i=0 ,t=0 ;i<A.size ();i++)if (i<B.size ()) t-=B[i];push_back ((t+10 )%10 );if (t<0 ) t=1 ;else t=0 ;while (C.size ()>1 &&C.back ()==0 ) C.pop_back ();return C;int main () int > A,B;for (int i=a.size ()-1 ;i>=0 ;i--) A.push_back (a[i]-'0' );for (int i=b.size ()-1 ;i>=0 ;i--) B.push_back (b[i]-'0' );if (cmp (A,B))auto C=sub (A,B);for (int i=C.size ()-1 ;i>=0 ;i--) cout<<C[i];else {auto C=sub (B,A);"-" ;for (int i=C.size ()-1 ;i>=0 ;i--) cout<<C[i];return 0 ;
## 高精度乘法
高精度X低精度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <vector> using namespace std;int > mul (vector <int > & A, int b) {int > C;int t = 0 ;for (int i = 0 ; i < A.size (); i ++) {push_back (t % 10 ); 10 ; while (t) { push_back (t % 10 );10 ;while (C.size () > 1 && C.back () == 0 ) C.pop_back ();return C;int main () int b;int > A;for (int i = a.size () - 1 ; i >= 0 ; i --) A.push_back (a[i] - '0' );auto C = mul (A, b);for (int i = C.size () - 1 ; i >= 0 ; i --) {return 0 ;
高精度X高精度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> #include <vector> using namespace std;vector<int > mul (vector<int > &A, vector<int > &B) {vector<int > C (A.size() + B.size() + 7 , 0 ) ; for (int i = 0 ; i < A.size (); i++)for (int j = 0 ; j < B.size (); j++)int t = 0 ;for (int i = 0 ; i < C.size (); i++) { 10 ;10 ;while (C.size () > 1 && C.back () == 0 ) C.pop_back (); return C;int main () int > A, B;for (int i = a.size () - 1 ; i >= 0 ; i--)push_back (a[i] - '0' );for (int i = b.size () - 1 ; i >= 0 ; i--)push_back (b[i] - '0' );auto C = mul (A, B);for (int i = C.size () - 1 ; i >= 0 ; i--)return 0 ;
acwing例题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 793 高精度乘法0 ) A 和 B ,请你计算 A ×B 的值。A ,第二行包含整数 B 。A ×B 的值。1 ≤A 的长度≤100000 ,0 ≤B ≤10000 2 3 6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 高精度乘以低精度#include <iostream> #include <vector> #include <string> using namespace std;vector<int > mul (vector<int >&A,int b) int > C;int t=0 ;for (int i=0 ;i<A.size ();i++)push_back (t%10 );10 ;while (t)push_back (t%10 );10 ;while (C.size ()>1 &&C.back ()==0 ) C.pop_back (); return C;int main () int b;int > A;for (int i=a.size ()-1 ;i>=0 ;i--) A.push_back (a[i]-'0' );auto C=mul (A,b);for (int i=C.size ()-1 ;i>=0 ;i--) cout<<C[i];return 0 ;
高精度除法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 给定两个非负整数(不含前导 0 ) A ,B ,请你计算 A /B 的商和余数。A ,第二行包含整数 B 。1 ≤A 的长度≤100000 ,1 ≤B ≤10000 ,B 一定不为 0 7 2 3 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <vector> #include <string> #include <algorithm> using namespace std;vector<int > divide (vector<int >&A,int b,int &r) int > C;for (int i=A.size ()-1 ;i>=0 ;i--)10 +A[i];push_back (r/b);reverse (C.begin (),C.end ());while (C.size ()>1 &&C.back ()==0 ) C.pop_back ();return C;int main () int b,r=0 ;int > A;for (int i=a.size ()-1 ;i>=0 ;i--) A.push_back (a[i]-'0' );auto C=divide (A,b,r);for (int i=C.size ()-1 ;i>=0 ;i--) cout<<C[i];return 0 ;
leetcode67题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 67 . 二进制求和1 和 0 。1 :a = "11" , b = "1" "100" 2 :a = "1010" , b = "1011" "10101" '0' 或 '1' 组成。1 <= a .length , b .length <= 10 ^4 "0" ,就都不含前导零。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public :string addBinary (string a, string b) {int >A,B;for (int i=a.size ()-1 ;i>=0 ;i--) A.push_back (a[i]-'0' );for (int i=b.size ()-1 ;i>=0 ;i--) B.push_back (b[i]-'0' );int t=0 ;for (int i=0 ;i<A.size ()||i<B.size ();i++)if (i<A.size ()) t+=A[i];if (i<B.size ()) t+=B[i];2 +'0' );2 ;if (t) C+=(1 +'0' );reverse (C.begin (),C.end ());return C;
前缀和
一维前缀和
将A[1]+…A[n] (n为变量)的值一一单独存入另一个数组中,然后查找区间的前缀和时,只要S[R]-S[L-1]即可得到区间前缀和(为啥是l-1,因为S[R]=A[1]+…A[R],S[L-1]=A[1]+…+A[L-1],两个相减就可以得到A[L]+…+A[R]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 795 前缀和n 的整数序列。n 和 m。n 个整数,表示整数数列。1 ≤l≤r≤n ,1 ≤n ,m≤100000 ,1000 ≤数列中元素的值≤1000 5 3 2 1 3 6 4 1 2 1 3 2 4 3 6 10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> using namespace std;const int N = 1e5 +10 ;int q[N],s[N];int main () sync_with_stdio (false );int n,m;for (int i=1 ;i<=n;i++) cin>>q[i];for (int i=1 ;i<=n;i++) s[i]=s[i-1 ]+q[i];while (m--)int l,r;-1 ]<<endl;return 0 ;
leetcode303
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 303. 区域和检索 - 数组不可变left 和 right (包含 left 和 right )之间的 nums 元素的 和 ,其中 left <= right int [] nums) 使用数组 nums 初始化对象int sumRange(int i, int j) 返回数组 nums 中索引 left 和 right 之间的元素的 总和 ,包含 left 和 right 两点(也就是 nums[left ] + nums[left + 1 ] + ... + nums[right ] )1 :-2 , 0 , 3 , -5 , 2 , -1 ]], [0 , 2 ], [2 , 5 ], [0 , 5 ]]null , 1 , -1 , -3 ]= new NumArray([-2 , 0 , 3 , -5 , 2 , -1 ]);0 , 2 ); / / return 1 ((-2 ) + 0 + 3 )2 , 5 ); / / return -1 (3 + (-5 ) + 2 + (-1 )) 0 , 5 ); / / return -3 ((-2 ) + 0 + 3 + (-5 ) + 2 + (-1 ))1 <= nums.length <= 104 -105 <= nums[i] <= 105 0 <= i <= j < nums.length104 次 sumRange 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class NumArray {public :int >sum;NumArray (vector<int >& nums) {push_back (0 );for (int i=1 ;i<=nums.size ();i++)push_back (sum[i-1 ]+nums[i-1 ]);int sumRange (int left, int right) return sum[right+1 ]-sum[left];
二维前缀和
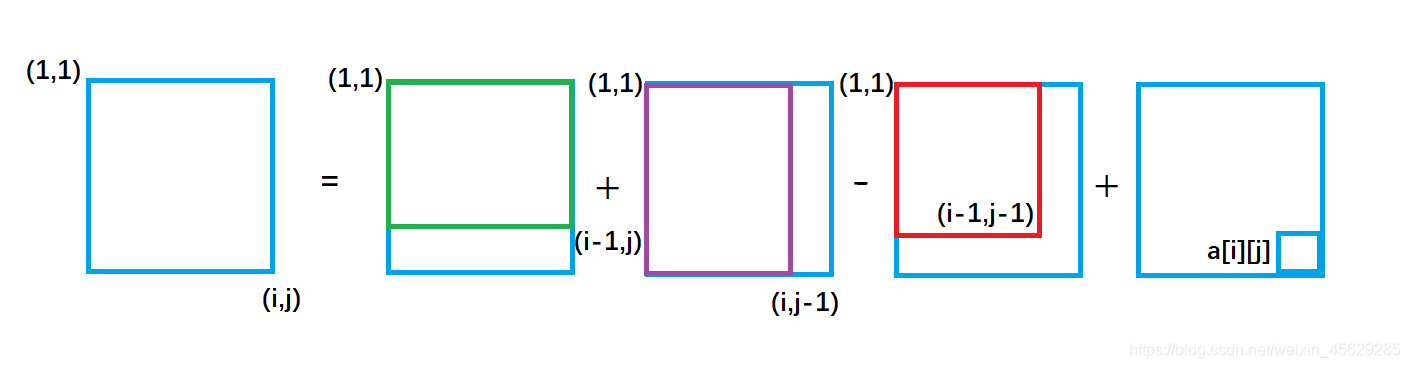
二维前缀和推导
紫色面积是指(1,1)左上角到(i,j-1)右下角的矩形面积, 绿色面积是指(1,1)左上角到(i-1, j )右下角的矩形面积。每一个颜色的矩形面积都代表了它所包围元素的和。
从图中我们很容易看出,整个外围蓝色矩形面积s[i] [j] = 绿色面积s[i-1] [j] + 紫色面积s[i] [j-1] - 重复加的红色的面积s[i-1] [j-1]+小方块的面积a[i] [j];
因此得出二维前缀和预处理公式
s[i] [j] = s[i-1] [j] + s[i] [j-1 ] + a[i] [j] - s[i-1] [ j-1] (是离散的数,不是面积哈)
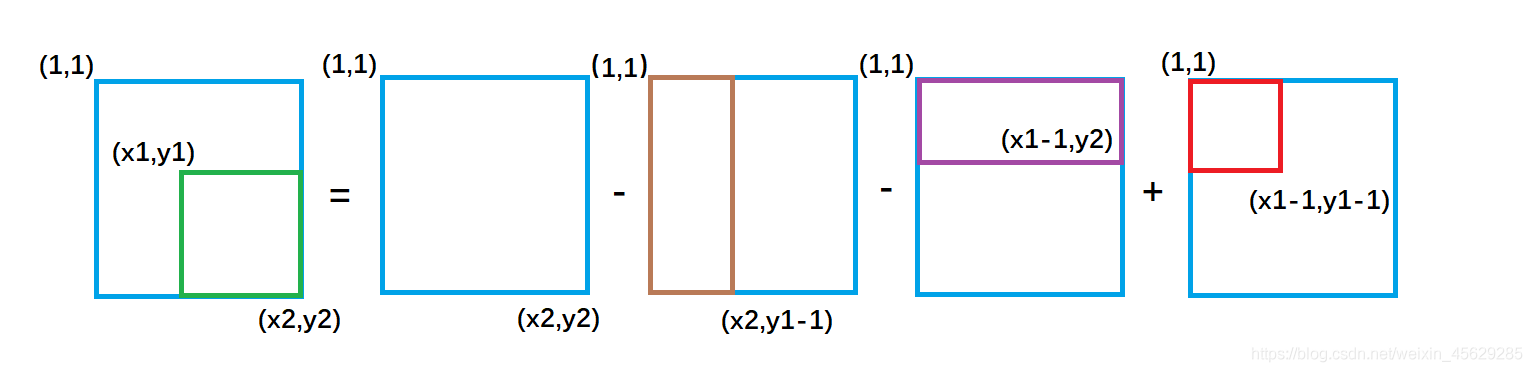
接下来回归问题去求以(x1,y1)为左上角和以(x2,y2)为右下角的矩阵的元素的和。
如图:
紫色面积是指 ( 1,1 )左上角到(x1-1,y2)右下角的矩形面积 ,黄色面积是指(1,1)左上角到(x2,y1-1)右下角的矩形面积;
不难推出:
绿色矩形的面积 = 整个外围面积s[x2, y2] - 黄色面积s[x2, y1 - 1] - 紫色面积s[x1 - 1, y2] + 重复减去的红色面积 s[x1 - 1, y1 - 1]
因此二维前缀和的结论为:
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 796 二维前缀和 4 3 7 2 4 6 2 8 1 2 3 1 2 2 1 3 4 3 3 4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> using namespace std;const int N=1e3 +10 ;int a[N][N],s[N][N];int main () int n,m,q;for (int i=1 ;i<=n;i++)for (int j=1 ;j<=m;j++)scanf ("%d" ,&a[i][j]);for (int i=1 ;i<=n;i++)for (int j=1 ;j<=m;j++)-1 ][j]+s[i][j-1 ]-s[i-1 ][j-1 ]+a[i][j];while (q--)int x1,x2,y1,y2;printf ("%d\n" ,s[x2][y2]-s[x1-1 ][y2]-s[x2][y1-1 ]+s[x1-1 ][y1-1 ]);return 0 ;
leetcode304
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 304. 二维区域和检索 - 矩阵不可变NumMatrix 类:NumMatrix (int[][] matrix) 给定整数矩阵 matrix 进行初始化1 :"NumMatrix" ,"sumRegion" ,"sumRegion" ,"sumRegion" ]3 ,0 ,1 ,4 ,2 ],[5 ,6 ,3 ,2 ,1 ],[1 ,2 ,0 ,1 ,5 ],[4 ,1 ,0 ,1 ,7 ],[1 ,0 ,3 ,0 ,5 ]]],[2 ,1 ,4 ,3 ],[1 ,1 ,2 ,2 ],[1 ,2 ,2 ,4 ]]8 , 11 , 12 ]NumMatrix numMatrix = new NumMatrix ([[3 ,0 ,1 ,4 ,2 ],[5 ,6 ,3 ,2 ,1 ],[1 ,2 ,0 ,1 ,5 ],[4 ,1 ,0 ,1 ,7 ],[1 ,0 ,3 ,0 ,5 ]]);2 , 1 , 4 , 3 ); // return 8 (红色矩形框的元素总和)1 , 1 , 2 , 2 ); // return 11 (绿色矩形框的元素总和)1 , 2 , 2 , 4 ); // return 12 (蓝色矩形框的元素总和)1 <= m, n <= 200 -105 <= matrix[i][j] <= 105 0 <= row1 <= row2 < m0 <= col1 <= col2 < n104 次 sumRegion 方法86 ,115 提交次数148 ,070
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class NumMatrix {public :int sum[2000 ][2000 ];NumMatrix (vector<vector<int >>& matrix) {int n=matrix.size (),m=matrix[0 ].size ();if (n>0 ){for (int i=1 ;i<=n;i++)for (int j=1 ;j<=m;j++)-1 ][j]+sum[i][j-1 ]-sum[i-1 ][j-1 ]+matrix[i-1 ][j-1 ];int sumRegion (int row1, int col1, int row2, int col2) return sum[row2+1 ][col2+1 ]-sum[row1][col2+1 ]-sum[row2+1 ][col1]+sum[row1][col1];
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class NumMatrix {public :int >> sum;NumMatrix (vector<vector<int >>& matrix) {int n=matrix.size (),m=matrix[0 ].size ();if (n>0 ){resize (n+1 ,vector <int >(m+1 ,0 ));for (int i=1 ;i<=n;i++)for (int j=1 ;j<=m;j++)-1 ][j]+sum[i][j-1 ]-sum[i-1 ][j-1 ]+matrix[i-1 ][j-1 ];int sumRegion (int row1, int col1, int row2, int col2) return sum[row2+1 ][col2+1 ]-sum[row1][col2+1 ]-sum[row2+1 ][col1]+sum[row1][col1];
差分
一维差分
详细知识链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 输入一个长度为 n 的整数序列。 2 2 1 2 1 3 1 5 1 6 1 4 5 3 4 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> using namespace std;const int N=1e5 +10 ;int a[N],b[N];int main () sync_with_stdio (false );int n,m;for (int i=1 ;i<=n;i++) cin>>a[i];for (int i=1 ;i<=n;i++) b[i]=a[i]-a[i-1 ];while (m--)int l,r,c;1 ]-=c;for (int i=1 ;i<=n;i++) a[i]=a[i-1 ]+b[i];for (int i=1 ;i<=n;i++) cout<<a[i]<<" " ;return 0 ;
y总版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;const int N=1e5 +10 ;int a[N],b[N];void insert (int l,int r,int c) 1 ]-=c;int main () int n,m;sync_with_stdio (false );for (int i=1 ;i<=n;i++) cin>>a[i];for (int i=1 ;i<=n;i++) insert (i,i,a[i]);while (m--)int l,r,c;insert (l,r,c);for (int i=1 ;i<=n;i++) b[i]+=b[i-1 ];for (int i=1 ;i<=n;i++) cout<<b[i]<<" " ;return 0 ;
二维差分
二维差分知识点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 798. 差分矩阵 5 个整数 x1,y1,x2,y2,c,表示一个操作。 4 3 2 2 1 2 2 1 1 1 1 1 2 2 1 3 2 3 2 1 3 4 1 3 4 1 3 4 1 2 2 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;const int N=1e3 +10 ;int a[N][N],b[N][N],matrix[N][N];int main () int n,m,q;sync_with_stdio (false );for (int i=1 ;i<=n;i++) for (int j=1 ;j<=m;j++)while (q--)int x1,y1,x2,y2,c;1 ][y1]-=c;1 ]-=c;1 ][y2+1 ]+=c;for (int i=1 ;i<=n;i++)for (int j=1 ;j<=m;j++)-1 ][j]+matrix[i][j-1 ]+b[i][j]-matrix[i-1 ][j-1 ];for (int i=1 ;i<=n;i++){for (int j=1 ;j<=m;j++)" " ;return 0 ;
双指针算法
找双指针算法可以先写一个暴力的o(n^2),然后找i和j是否满足单调性,如果满足就可以使用双指针算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 799 . 最长连续不重复子序列n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。n 。n 个整数(均在 0 ∼105 范围内),表示整数序列。1 ≤n ≤105 5 1 2 2 3 5 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> using namespace std;const int N=1e5 +10 ;int a[N],s[N];int main () sync_with_stdio (false );int n;int res=0 ;for (int i=0 ;i<n;i++) cin>>a[i];for (int i=0 ,j=0 ;i<n;i++)while (s[a[i]]>1 )max (res,i-j+1 );return 0 ;
链表的定义
链表是物理存储单元上非连续 的、非顺序 的存储结构,它是由一个个结点,通过指针来联系起来的,其中每个结点包括数据和指针。
链表在内存中采用每个结点都分配在非连续 的位置,结点与结点之间通过指针连在了一起,查找元素时需要遍历查找。
链表的表示
定义头节点:
由于链表的特点(查询或删除元素都要从头结点开始),所以我们只要在链表中定义头结点即可(我学习采用的是头节点无数据型的链表表示):
1 2 3 4 5 6 7 8 9 10 11 typedef struct Node {int data;struct Node * next ;createList () malloc (sizeof (Node));NULL ;return headNode;
创建节点:
创建完头节点后我们需要创建新的节点用来存储数据:
1 2 3 4 5 6 7 8 Node* createNode (int data) malloc (sizeof (Node));NULL ;return newNode;
连接节点:
链接节点可以采用两种方式:1. 头插法 2.尾插法
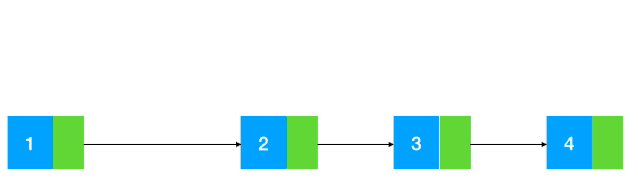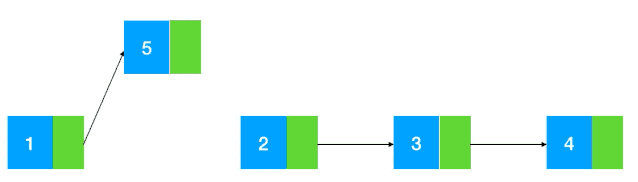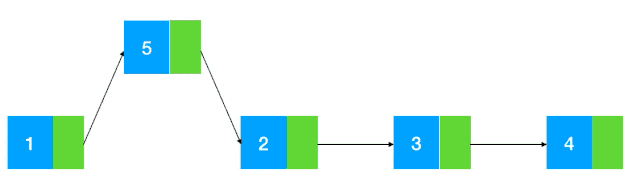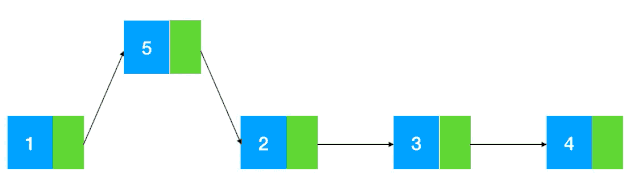
头插法:
具体步骤如上图所示,将将前一个节点指向插入的节点,将插入的节点指向原下一个节点
1 2 3 4 5 6 7 void insertList (Node* headNode,int data)
尾插法(一):
观察头插法会发现,插入节点时永远会在头节点插入,导致数据是逆序的。那么只要数据都是在链表的最后插入就不会有这个问题。尾插法在头插法的基础上,设置了一个单独的结构体指针保证结构体在插入时永远是在尾巴插入,这样数据存储就是顺序的。
这种尾插法有一个缺点,就是只能连续插入,不能分开插入,所以我们就有了第二种尾插法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Node* LinkList () malloc (sizeof (Node));NULL ;while (1 )int data;printf ("请输入您的数据:" );scanf ("%d" ,&data);if (data==5 ) break ;return headNode;
尾插法(二)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int main () 1 );2 );3 );return 0 ;LinkList (Node **ptail,int data) return (*ptail);
在任意位置插入节点
在任意处插入节点的重要点就在于要先找到要插入位置的地址,因为链表只能知道下一个节点,所以必须要遍历查找,并返回节点的地址,然后插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 Node* foundNode (Node* headNode,int searchdata) int isFound=0 ;for (pFound=headNode->next;pFound;pFound=pFound->next)if (pFound->data==searchdata){printf ("找到了\n" );1 ;return pFound;if (!isFound) printf ("没找到\n" );return NULL ;void insertNode (Node** pFound,int data) int main () 1 );2 );3 );4 );2 );6 );return 0 ;
打印链表
链表只能循环打印
1 2 3 4 5 6 7 8 9 10 11 void printList (Node* headNode) printf ("打印链表\n" );while (pMove)printf ("%d->" ,pMove->data);printf ("NULL\n" );
查找链表
查找链表我暂时只学到遍历查找,等后续学到了会更新
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void searchNode (Node* headNode,int searchdata) int isFound=0 ;while (pMove)if (pMove->data==searchdata)printf ("在此链表中找到了!\n" );1 ;break ;if (!isFound) printf ("对不起没有找到!\n" );
删除节点
一样的只会循环查找后删除,后续更新新的方法
删除节点有几个要注意的地方:
一:首先要定义两个指针,因为删除节点需要该节点的前节点链接到该节点的下一个节点,而单链表只能知道下一个节点,所以必须要两个指针来删除
二:就是要注意,当删除的节点是头节点,那么就必须特殊对待,直接将headNode指向删掉节点的下一个节点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void deleteNode (Node* headNode,int deletenumber) int isFound=0 ;for (q=NULL ,p=headNode->next;p;q=p,p=p->next)if (p->data==deletenumber)1 ;if (!q)else free (p);break ;if (!isFound) printf ("未删除成功\n" );else printf ("删除成功\n" );
静态链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> using namespace std;const int N=1e5 ;int val[N],ne[N],head[N],idx;void init () -1 ;0 ;void add-to-head (int x)void add (int pos,int x) void remove (int pos) int main () init ();return 0 ;
826. 单链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 k 个插入的数后面的数;k 个插入的数后插入一个数。M 次操作,进行完所有操作后,从头到尾输出整个链表。: 题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。M ,表示操作次数。M 行,每行包含一个操作命令,操作命令可能为以下几种:H x ,表示向链表头插入一个数 x 。D k ,表示删除第 k 个插入的数后面的数(当 k 为 0 时,表示删除头结点)。I k x ,表示在第 k 个插入的数后面插入一个数 x (此操作中 k 均大于 0 )。1 ≤M ≤100000 10 H 9 I 1 1 D 1 D 0 H 6 I 3 6 I 4 5 I 4 5 I 3 4 D 6 6 4 6 5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <iostream> #include <algorithm> using namespace std;const int N=1e5 +10 ;int val[N],ne[N],head,idx;void init () -1 ;0 ;void add_to_head (int x) void deletex (int k) void add (int k,int x) int main () sync_with_stdio (false );init ();char oper;int n,x,k;while (n--)if (oper=='H' ){add_to_head (x);else if (oper=='I' ){add (k-1 ,x);else {if (x==0 ) head=ne[head];deletex (x-1 );int index=head;while (index!=-1 )" " ;return 0 ;
## 双链表
双链表具体详解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 827. 双链表 5 种操作: 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。 2 10 2 7 4 7 2 2 7 7 3 2 9
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <iostream> #include <string> using namespace std;const int N=1e5 +10 ;int val[N],l[N],r[N],idx;void insert (int k,int x) void init () 0 ]=1 ;1 ]=0 ;2 ;void remove (int k) int main () init ();int n;while (n--)int k,x;if (oper=="L" )insert (0 ,x);else if (oper=="R" )insert (l[1 ],x);else if (oper=="IL" )insert (l[k+1 ],x);else if (oper=="IR" )insert (k+1 ,x);else {remove (k+1 );int cnt=r[0 ];while (cnt!=1 )" " ;return 0 ;
栈和单调栈
表达式求值(栈的应用)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 828 . 模拟栈x – 向栈顶插入一个数 x ;pop – 从栈顶弹出一个数;empty – 判断栈是否为空;3 和操作 4 都要输出相应的结果。x ,pop ,empty ,query 中的一种。empty 和 query 操作都要输出一个查询结果,每个结果占一行。empty 操作的查询结果为 YES 或 NO,query 操作的查询结果为一个整数,表示栈顶元素的值。1 ≤M≤100000 ,1 ≤x ≤109 10 5 6 pop pop empty 4 empty 5 5 4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <stack> #include <cstring> #include <algorithm> #include <unordered_map> #include <cctype> using namespace std;int > num;int > op;void eval () int ans=0 ;int b=num.top ();num.pop ();int a=num.top ();num.pop ();char operation=op.top ();op.pop ();if (operation=='+' ) ans=a+b;if (operation=='-' ) ans=a-b;if (operation=='*' ) ans=a*b;if (operation=='/' ) ans=a/b;push (ans);int main () char ,int > h={{'+' ,1 },{'-' ,1 },{'*' ,2 },{'/' ,2 }};for (int i=0 ;i<s.size ();i++)if (isdigit (s[i])){int j=i,a=0 ;while (j<s.size ()&&isdigit (s[j]))10 +s[j]-'0' ;push (a);-1 ;else if (s[i]=='(' ) op.push (s[i]);else if (s[i]==')' )while (op.top ()!='(' ) eval ();pop ();else {while (op.size ()&&h[op.top ()]>=h[s[i]]) eval ();push (s[i]);while (op.size ()) eval ();top ()<<endl;return 0 ;
模拟队列和单调队列
模拟队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 实现一个队列,队列初始为空,支持四种操作:push x – 向队尾插入一个数 x;pop – 从队头弹出一个数;3 和操作 4 都要输出相应的结果。push x,pop ,empty,query 中的一种。1 ≤M≤100000 ,1 ≤x≤109 ,10 push 6 pop push 3 push 4 pop push 6 6 4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <string> using namespace std;const int N=1e5 +10 ;int queue[N],head,tt=-1 ;void push (int x) void pop () int empty () if (head<=tt) return 0 ;else return 1 ;int query () return queue[head];int main () int n;while (n--)if (operation=="push" )int x;push (x);if (operation=="pop" )pop ();if (operation=="empty" )if (!empty ()) cout<<"NO" <<endl;else cout<<"YES" <<endl;if (operation=="query" )query ()<<endl;return 0 ;
单调队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 154. 滑动窗口-1 -3 5 3 6 7],k 为 3。-1 ] -3 5 3 6 7 -1 3-1 -3 ] 5 3 6 7 -3 3-1 -3 5] 3 6 7 -3 5-1 [-3 5 3] 6 7 -3 5-1 -3 [5 3 6] 7 3 6-1 -3 5 [3 6 7] 3 7-1 -3 5 3 6 7-1 -3 -3 -3 3 3
思路:
最小值和最大值分开来做,两个for循环完全类似,都做以下四步:
解决队首已经出窗口的问题;
解决队尾与当前元素a[i]不满足单调性的问题;
将当前元素下标加入队尾;
如果满足条件则输出结果;
需要注意的细节:
上面四个步骤中一定要先3后4,因为有可能输出的正是新加入的那个元素
队列中存的是原数组的下标,取值时要再套一层,a[q[]];
算最大值前注意将hh和tt重置;
此题用cout会超时,只能用printf;
hh从0开始,数组下标也要从0开始。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> #include <string> using namespace std;const int N=1e6 +10 ;int hh,tt=-1 ,a[N],q[N];int main () int n,k;for (int i=0 ;i<n;i++) cin>>a[i];for (int i=0 ;i<n;i++)if (hh<=tt&&k<i-q[hh]+1 ) hh++;while (hh<=tt&&a[q[tt]]>=a[i]) tt--; if (i>=k-1 ) cout<<a[q[hh]]<<" " ;0 ,tt=-1 ;for (int i=0 ;i<n;i++){if (hh<=tt&&k<i-q[hh]+1 ) hh++;while (hh<=tt&&a[q[tt]]<=a[i]) tt--;if (i>=k-1 ) cout<<a[q[hh]]<<" " ;return 0 ;
堆
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <iostream> #include <string> using namespace std;const int N=1e5 +10 ;int h[N],hp[N],ph[N],cur_size,m;void heap_swap (int a,int b) swap (ph[hp[a]],ph[hp[b]]);swap (hp[a],hp[b]);swap (h[a],h[b]);void up (int x) while (x/2 &&h[x/2 ]>h[x])heap_swap (x,x/2 );1 ;void down (int x) int t=x;if (x*2 <=cur_size&&h[2 *x]<h[t]) t=2 *x;if (x*2 +1 <=cur_size&&h[2 *x+1 ]<h[t]) t=2 *x+1 ;if (x!=t)heap_swap (t,x);down (t);int main () int n;while (n--)if (op=="I" )int x;up (cur_size);else if (op=="PM" ) cout<<h[1 ]<<endl;else if (op=="DM" )heap_swap (1 ,cur_size);down (1 );else if (op=="D" )int x;int k=ph[x];heap_swap (ph[x],cur_size);down (k);up (k);else {int k,x;down (ph[k]);up (ph[k]);return 0 ;
KMP
KMP全称为Knuth Morris Pratt算法,三个单词分别是三个作者的名字。KMP是一种高效的字符串匹配算法,用来在主字符串中查找模式字符串的位置(比如在“hello,world”主串中查找“world”模式串的位置)。
KMP算法的高效体现在哪
高效性是通过和其他字符串搜索算法对比得到的,在这里拿BF(Brute Force)算法做一下对比。BF算法是一种最朴素的暴力搜索算法。它的思想是在主串的[0, n-m]区间内依次截取长度为m的子串,看子串是否和模式串一样(n是主串的长度,m是子串的长度)。
下面通过一个具体的例子来看看可以跳过的情况。比如主模式串是”ababaeaba”,模式串是”ababacd”,在BF算法中,遇到不匹配的情况是这样处理的:
1 2 3 main: "ababaeaba" // 例如这两个串,当sub 为"ababaea" 时和"ababacd" 进行对pattern: "ababacd" // 比,当main[i]为e时,发现和pattern[j]的值e不一致,BFsub ,即用"babaeab" 和pattern进行比较。
我没希望找到一些规律,遇到两个字符不匹配的情况时,希望可以多跳几个字符,减少比较次数。KMP算法的思想是:在模式串和主串匹配过程中,当遇到不匹配的字符时,对于主串和模式串中已对比过相同的前缀字符串,找到长度最长的相等前缀串,从而将模式串一次性滑动多位,并省略一些比较过程。在上个例子,KMP算法中,是这样处理的:
1 2 3 4 5 6 7 8 9 10 11 12 13 main: "ababaeaba" // 比如main中的"ababa" 子串,对标为[2 ~4 ]的"aba" 和pattern中下"ababacd" // 标为[0 ~2 ]的"aba" 相同,此时可以滑动j-k位,即j=j-k。(其中j是// pattern中"c" 的下标,k是"abc" 的长度)。"ababaeaba" // 比较过程中,main[5 ]为"e" 和pattern[5 ]为"c" 不匹配,但是两个"ababacd" // 串中都有相同的"aba" 前缀,所以可以滑动j-k位"ababaeaba" "ababacd" // 滑动j-k位后发现main[5 ]和patterb[3 ]不相同,需要再次滑动"ababaeaba" "ababacd" // 滑动过程和上次类似。
通过这个例子可以看出,每次滑动的位数是j-k,滑动位数和主串无关,仅通过模式串就可以求出。在KMP算法中通过next数组来存储当两个字符不相等时模式串应该移动的位数。
如何KMP算法的next数组
模式前缀
前缀结尾下标
最长能匹配前缀子串结尾字符的下标
next数组的取值
匹配情况
a
0
-1
next[0] = -1
无
ab
1
-1
next[1] = -1
无
aba
2
0
next[2]=0
pattern[2]==pattern[0]
abab
3
1
next[3]=1
pattern[2:4]==pattern[0:2]
ababa
4
2
next[4]=2
pattern[2:5]==pattern[0:3]
ababac
5
-1
next[5]=-1
无
KMP的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <string> #include <algorithm> using namespace std;const int N=100010 ,M=1000010 ;int n,m,ne[N];char p[N],s[M];int main () 1 >>m>>s+1 ;for (int i=2 ,j=0 ;i<=n;i++)while (j&&p[i]!=p[j+1 ]) j=ne[j];if (p[i]==p[j+1 ]) j++;for (int i=1 ,j=0 ;i<=m;i++)while (j&&s[i]!=p[j+1 ]) j=ne[j];if (s[i]==p[j+1 ]) j++;if (j==n)" " ;return 0 ;
Trie
哈希表
拉链法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> #include <cstring> using namespace std;const int N=1e5 +3 ;int h[N],ne[N],e[N],idx,n;void insert (int x) int k=(x%N+N)%N;bool query (int x) bool flag=false ;int k=(x%N+N)%N;for (int i=h[k];i!=-1 ;i=ne[i])if (e[i]==x){true ;break ;return flag;int main () memset (h,-1 ,sizeof h);while (n--)int x;if (op=="I" ) insert (x);else {if (query (x)) cout<<"Yes" <<endl;else cout<<"No" <<endl;return 0 ;
开放寻址法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> #include <cstring> using namespace std;const int N=200003 ,null=0x3f3f3f3f ;int h[N],n;int find (int x) int k=(x%N+N)%N;while (h[k]!=null&&h[k]!=x)if (k==N) k=0 ;return k;int main () memset (h,0x3f ,sizeof h);while (n--)int x;if (op=="I" )int k=find (x);else {if (h[find (x)]==null) cout<<"No" <<endl;else cout<<"Yes" <<endl;return 0 ;
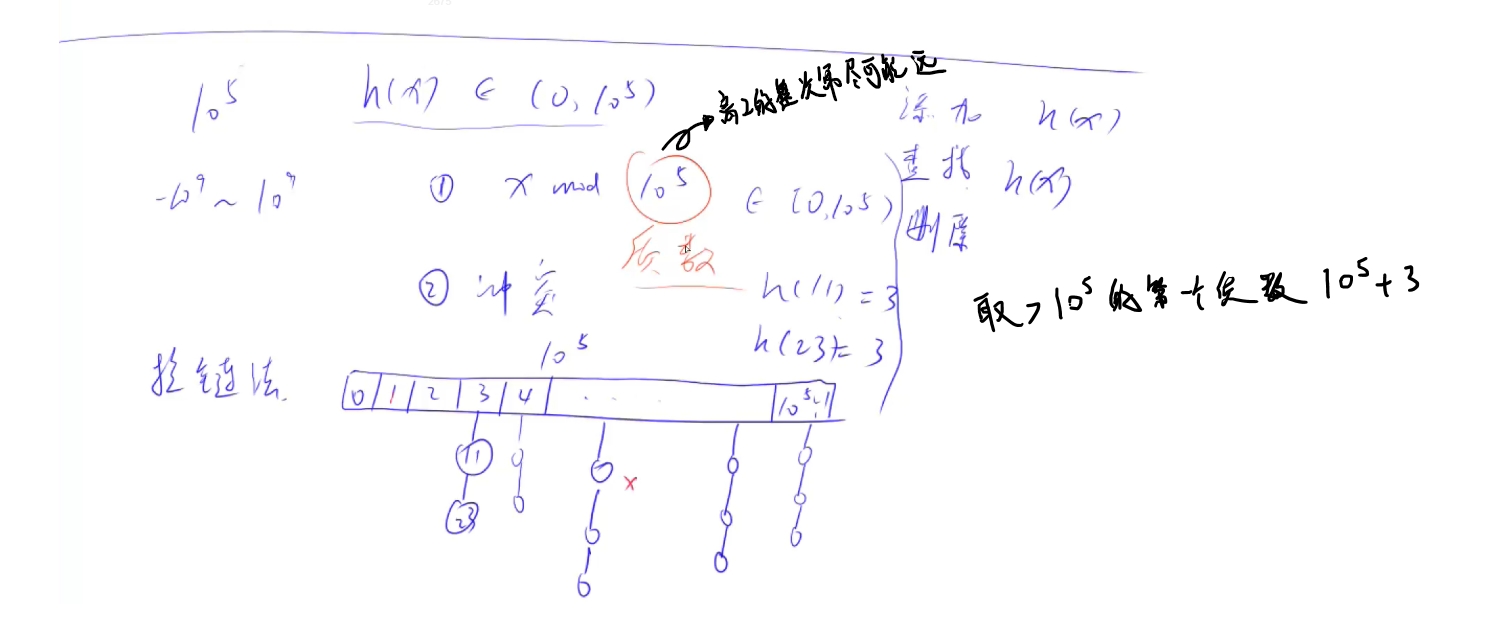
字符串哈希表
(字符串哈希) O(n)+O(m)
映射公式 (X1×Pn−1+X2×Pn−2+⋯+Xn−1×P1+Xn×P0)modQ
任意字符不可以映射成0,否则会出现不同的字符串都映射成0的情况,比如A,AA,AAA皆为0
冲突问题:通过巧妙设置P (131 或 13331) , Q (264)(264)的值,一般可以理解为不产生冲突。
问题是比较不同区间的子串是否相同,就转化为对应的哈希值是否相同。
前缀和公式 h[i+1]=h[i]×P+s[i]h[i+1]=h[i]×P+s[i] i∈[0,n−1]i∈[0,n−1] h为前缀和数组,s为字符串数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #include <iostream> #include <cstring> using namespace std;typedef unsigned long long ull;const int N=1e5 +10 ,P=131 ;char str[N];int get_val (int l, int r) return h[r]-h[l-1 ]*p[r-l+1 ];int main () int n,m;scanf ("%s" ,str+1 );0 ]=1 ;for (int i=1 ;i<=n;i++)-1 ]*P;-1 ]*P+str[i];while (m--)int l1,r1,l2,r2;if (get_val (l1,r1)==get_val (l2,r2)) cout<<"Yes" <<endl;else cout<<"No" <<endl;return 0 ;
在计算最短路时,Dijkstra算法不能处理带有负权的图,bellman_ford和spfa可以处理带有负权边的图,spfa是对bellman_ford的优化。
图论
Dijkstra算法
在Dijkstra算法中,稠密图使用邻接矩阵,稀疏图使用邻接表
朴素Dijkstra算法
在使用Dijkstra算法时,如果有向图中出现重边或者是有环的话,只采用代价最小的边
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 给定一个 n 个点 m条边的有向图,图中可能存在重边和自环,所有边权均为正值。1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 −1 。n 和 m。1 号点到 n 号点的最短距离。1 。1 ≤n ≤500 ,1 ≤m≤105 ,10000 。3 3 1 2 2 2 3 1 1 3 4 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> #include <algorithm> #include <cstring> using namespace std;const int N=510 ;int n,m,g[N][N],dist[N];bool st[N];int dijkstra () memset (dist,0x3f ,sizeof dist);1 ]=0 ;for (int i=1 ;i<=n;i++){int t=-1 ;for (int j=1 ;j<=n;j++)if (!st[j]&&(t==-1 ||dist[t]>dist[j]))true ;for (int j=1 ;j<=n;j++)min (dist[j],dist[t]+g[t][j]);if (dist[n]==0x3f3f3f3f ) return -1 ;else return dist[n];int main () memset (g,0x3f ,sizeof g);while (m--)int a,b,c;min (g[a][b],c);int t = dijkstra ();return 0 ;
堆优化Dijkstra算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 给定一个 n 个点 m条边的有向图,图中可能存在重边和自环,所有边权均为非负值。1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 −1 。n 和 m。1 号点到 n 号点的最短距离。如果路径不存在,则输出 −1 。1 ≤n ,m≤1.5 ×105 ,0 ,且不超过 10000 。数据保证:如果最短路存在,则最短路的长度不超过 109 。3 3 1 2 2 2 3 1 1 3 4 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> #include <cstring> #include <algorithm> #include <queue> using namespace std;const int N=2e5 ;int h[N],n,m,ne[N],val[N],idx,w[N],dist[N];bool state[N];typedef pair<int ,int > PII;void add (int a,int b,int c) int dijkstra () memset (dist,0x3f ,sizeof dist);1 ]=0 ;push ({0 ,1 });while (q.size ())auto t = q.top ();pop ();int ver = t.second,distance = t.first;if (state[ver]) continue ;true ;for (int i=h[ver];i!=-1 ;i=ne[i])int j=val[i];if (dist[j]>dist[ver]+w[i]){ push ({dist[j],j});if (dist[n]==0x3f3f3f3f ) return -1 ;else return dist[n];int main () memset (h,-1 ,sizeof h);while (m--)int a,b,c;add (a,b,c);auto t=dijkstra ();return 0 ;
bellman_ford
Bellman-ford 算法是求含负权图的单源最短路径的一种算法,效率较低,代码难度较小。其原理为连续进行松弛,在每次松弛时把每条边都更新一下,若在 n-1 次松弛后还能更新,则说明图中有负环,因此无法得出结果,否则就完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 给定一个 n 个点 m条边的有向图,图中可能存在重边和自环, 边权可能为负数。1 号点到 n 号点的最多经过 k条边的最短距离,如果无法从 1 号点走到 n 号点,输出 impossible。n ,m,k。1 ∼n 。1 号点到 n 号点的最多经过 k条边的最短距离。1 ≤n ,k≤500 ,1 ≤m≤10000 ,1 ≤x,y≤n ,10000 。3 3 1 1 2 1 2 3 1 1 3 3 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N=510 ,M=1e5 +10 ;int dist[N],backup[N],n,m,k;struct edge int a,b,w;void bellman_ford () memset (dist,0x3f ,sizeof dist);1 ]=0 ;for (int i=0 ;i<k;i++)memcpy (backup,dist,sizeof dist);for (int j=0 ;j<m;j++)int a=edge[j].a,b=edge[j].b,w=edge[j].w;if (dist[b]>backup[a]+w)int main () for (int i=0 ;i<m;i++)int a,b,w;bellman_ford ();if (dist[n]>0x3f3f3f3f /2 ) cout<<"impossible" <<endl;else cout<<dist[n]<<endl;return 0 ;
spfa算法
Bellman_ford算法会遍历所有的边,但是有很多的边遍历了其实没有什么意义,我们只用遍历那些到源点距离变小的点所连接的边即可,只有当一个点的前驱结点更新了,该节点才会得到更新;因此考虑到这一点,我们将创建一个队列每一次加入距离被更新的结点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 给定一个 n 个点 m条边的有向图,图中可能存在重边和自环, 边权可能为负数。1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 impossible。n 和 m。1 号点到 n 号点的最短距离。1 ≤n ,m≤105 ,10000 。3 3 1 2 5 2 3 -3 1 3 4 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> #include <cstring> #include <queue> using namespace std;const int N=2e5 ;int head[N],val[N],ne[N],w[N],idx,dist[N],n,m;bool state[N];void add (int a,int b,int c) void spfa () memset (dist,0x3f ,sizeof dist);1 ]=0 ;int > q;1 ]=true ;push (1 );while (q.size ())int t=q.front ();pop ();false ;for (int i=head[t];i!=-1 ;i=ne[i])int j = val[i];if (dist[j]>dist[t]+w[i]) if (!state[j]){push (j);true ;int main () memset (head,-1 ,sizeof head);for (int i=0 ;i<m;i++)int a,b,c;add (a,b,c);spfa ();if (dist[n]==0x3f3f3f3f ) cout<<"impossible" <<endl;else cout<<dist[n]<<endl;return 0 ;
树
先序创建二叉树
算法思想
先序创建二叉树采用递归的方式实现,先传入二叉树的根节点指针的地址,然后依次递归读入二叉树节点,当读入的是’@‘时,将递归得到的根节点赋予NULL,当读入的不为’@'时,将该值赋值到根节点值,并依此递归左儿子和右儿子。
关键问题1:为什么要传入根节点的地址?
因为我们已知的是根节点指针,它指向malloc开辟的BiTree空间的首地址,当传入的是根节点指针而不是根节点指针的地址时,在函数中会copy一个该根节点指针指向的空间。但我们如果传入的是根节点指针的地址,函数内部不会重新copy一个空间。
其思想与函数传入实参和形参相似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <algorithm> #include <string> #include "Traverser.cpp" using namespace std;typedef struct BiTree char data;struct BiTree *lchild,*rchild;void CreateBiTree (BiTree* &T) char ch;if (ch=='@' ) T=NULL ;else {malloc (sizeof (BiTree));CreateBiTree (T->lchild);CreateBiTree (T->rchild);void PreOrderTraverser (BiTree* &T) if (T)" " ;PreOrderTraverser (T->lchild);PreOrderTraverser (T->rchild);int main () CreateBiTree (root);PreOrderTraverser (root);return 0 ;
遍历二叉树
代码部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 #include <iostream> #include <algorithm> #include <string> #include <stack> #include <algorithm> #include <string> using namespace std;typedef struct BiTree char data;struct BiTree *lchild,*rchild;void CreateBiTree (BiTree* &T) char ch;if (ch=='@' ) T=NULL ;else {malloc (sizeof (BiTree));CreateBiTree (T->lchild);CreateBiTree (T->rchild);void PreOrderTraverser (BiTree *T) if (T)" " ;PreOrderTraverser (T->lchild);PreOrderTraverser (T->rchild);void InOrderTraverser (BiTree *T) if (T)InOrderTraverser (T->lchild);" " ;InOrderTraverser (T->rchild);void PostOrderTraverser (BiTree *T) if (T)PostOrderTraverser (T->lchild);PostOrderTraverser (T->rchild);" " ;void InOrderTraverser_2 (BiTree* T) while (p||op.size ())if (p){push (p);else {top (); pop ();" " ; void PreOrderTraverser_2 (BiTree* T) while (p||op.size ())if (p){" " ;push (p);else {top ();pop ();int main () CreateBiTree (root);PreOrderTraverser (root);PreOrderTraverser_2 (root);InOrderTraverser (root);InOrderTraverser_2 (root);PostOrderTraverser (root);return 0 ;
计算二叉树
代码部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <string> #include <algorithm> using namespace std;typedef struct BiTree char data;struct BiTree *lchild,*rchild;void CreateBiTree (BiTree* &T) char ch;if (ch=='@' ) T=NULL ;else {malloc (sizeof (BiTree));CreateBiTree (T->lchild);CreateBiTree (T->rchild);int BiTreeDepth (BiTree* T) if (!T) return 0 ;else {int m=BiTreeDepth (T->lchild);int n=BiTreeDepth (T->rchild);return m>n?(m+1 ):(n+1 );int CountNode (BiTree* T) if (T==NULL ) return 0 ;else return CountNode (T->lchild)+CountNode (T->rchild)+1 ;int CountLeaves (BiTree* T) int cnt=0 ;if (T==NULL ) return 0 ;if ((!T->lchild)&&(!T->rchild)) cnt++;;int lcnt=CountLeaves (T->lchild);int rcnt=CountLeaves (T->rchild);return cnt;int main () CreateBiTree (root);BiTreeDepth (root)<<endl;return 0 ;